Feature Driven and Point Process Approaches for Popularity Prediction
Abstract
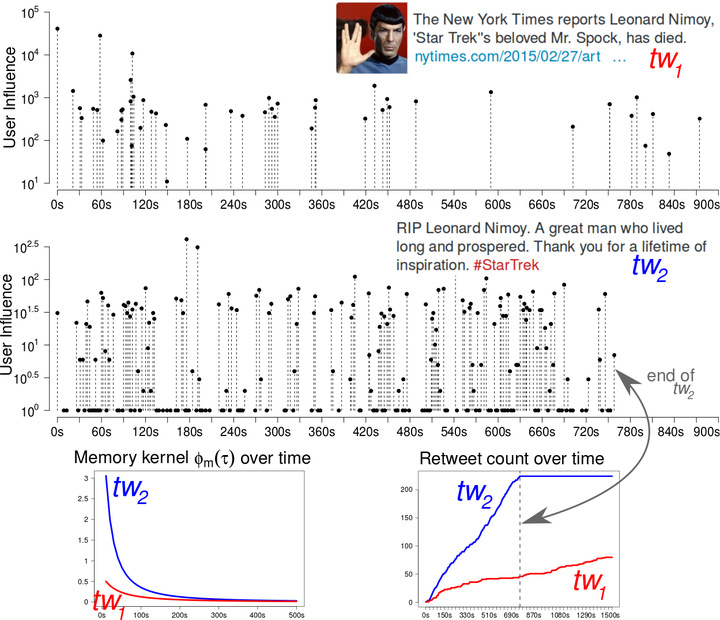
Predicting popularity, or the total volume of information outbreaks, is an important subproblem for understanding collective behavior in networks. Each of the two main types of recent approaches to the problem, feature-driven and generative models, have desired qualities and clear limitations. This paper bridges the gap between these solutions with a new hybrid approach and a new performance benchmark. We model each social cascade with a marked Hawkes self-exciting point process, and estimate the content virality, memory decay, and user influence. We then learn a predictive layer for popularity prediction using a collection of cascade history. To our surprise, Hawkes process with a predictive overlay outperform recent feature-driven and generative approaches on existing tweet data [44] and a new public benchmark on news tweets. We also found that a basic set of user features and event time summary statistics performs competitively in both classification and regression tasks, and that adding point process information to the feature set further improves predictions. From these observations, we argue that future work on popularity prediction should compare across feature-driven and generative modeling approaches in both classification and regression tasks.